
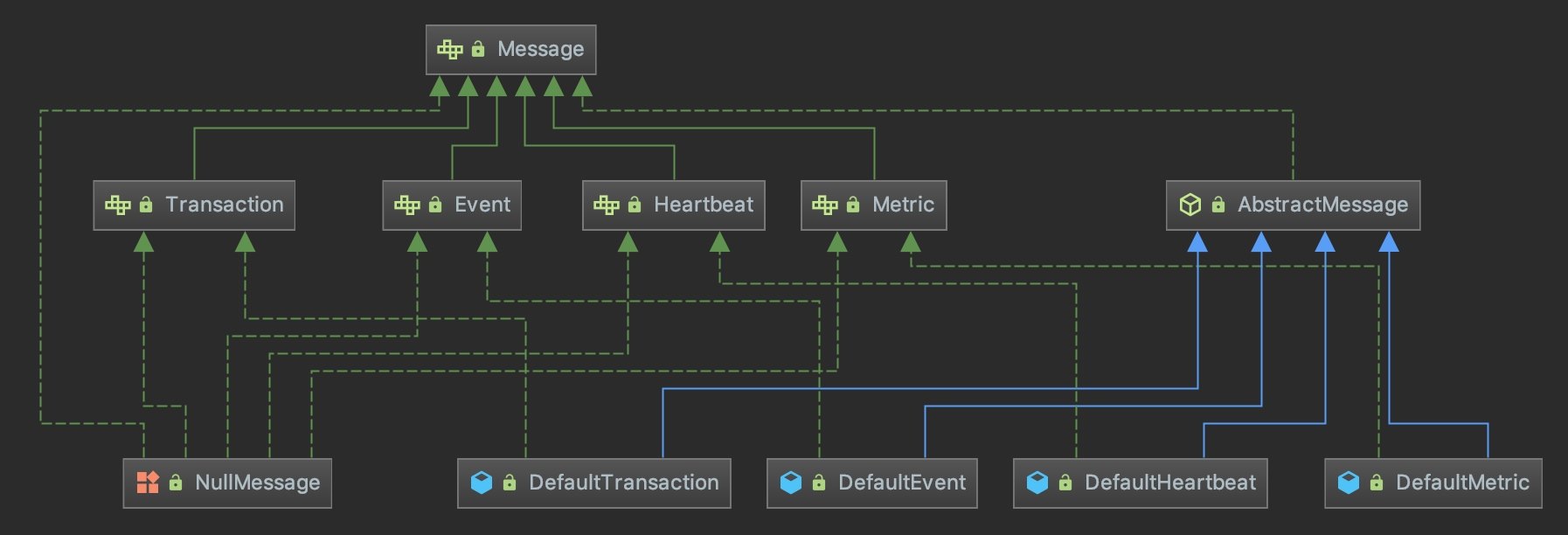
消息模型
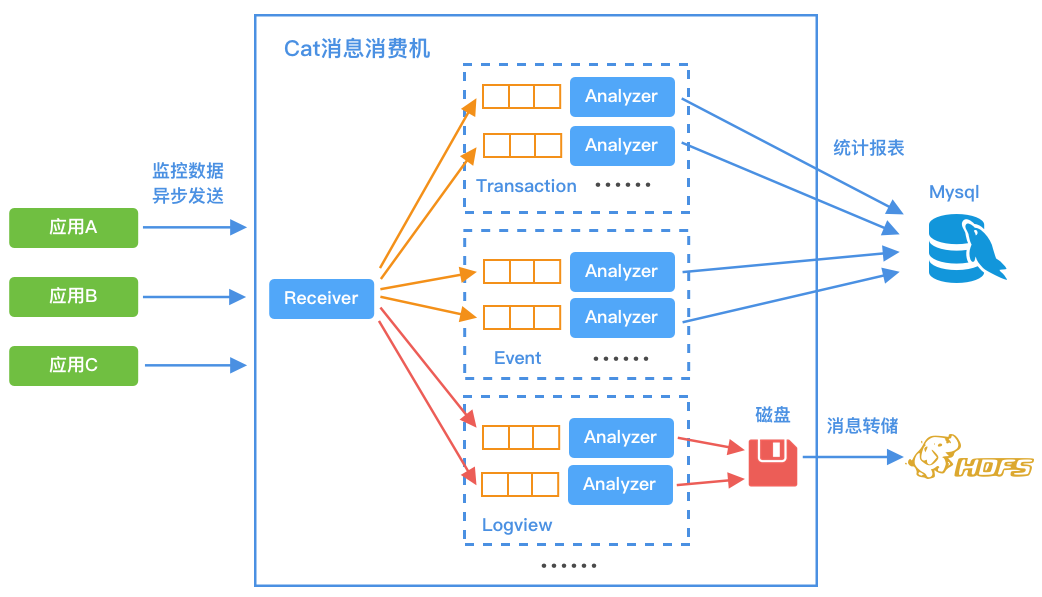
消息流水线
消息文件存储
CAT 针对消息写多读少的场景,设计并实现了一套文件存储。以小时为单位进行集中式存储,每个小时对应一个存储目录,存储文件分为索引文件和数据文件。用户可以根据 MessageID 快读定位到某一个消息。
消息 ID 设计
CAT 客户端会为每个消息树都会分配唯一的 MessageID,MessageID 总共分为四段,示例格式:shop.service-0a010101-431699-1000。
第一段是应用名shop.service。
第二段是客户端机器 IP 的16进制码,0a010101 表示10.1.1.1。
第三段是系统当前时间除以小时得到的整点数,431699 代表 2019-04-01 19:00:00。
第四段是客户端机器当前小时消息的连续递增号。(
存储设计的重要依据点)
文件存储 V1.0
总体概貌
V1.0 版本的文件存储设计比较简单粗暴,每个客户端 IP 节点对应分别对应一个索引文件和数据文件。
单个 IP 视角
每个索引内容由存储块首地址和块内偏移地址组成,共 6byte。
每个索引内容的序号与消息序列号一一对应,因为消息序列号是连续递增号,所以索引文件基本可以保证是顺序写。
为了减少磁盘IO交互和写入时间,消息采用批量 Gzip 压缩后顺序 append 至数据文件。
优缺点分析
文件存储 V2.0
V2.0 文件存储进行了重新设计,以解决 V2.0 数据文件节点过多以及随机 IO 恶化的问题。
总体概貌
V2.0 核心设计思想:
合并同一个应用的所有 IP 节点。
引入多级索引,建立 IP、Index、DataOffset 的映射关系。
同一个 IP 的索引数据尽可能保证顺序存储。
单个索引文件视角
索引文件存储的特点:
需要根据 IP + Index 建立一级索引。
不同 IP 节点跳跃式存储,每次划分一段连续且固定大小的存储空间。
同一个 IP 节点根据 Index 在每块固定大小的存储空间内顺序存储。
最小索引单元视角
上图是索引结构的最小单元,每个索引文件由若干个最小单元组成。每个单元分为 4 * 1024 个 Segment,第一个 Segment 作为我们的一级索引 Header,存储 IP、消息序列号与 Segment 的映射信息。剩余 4 * 1024 - 1 个 Segment 作为二级索引,存储消息的地址。一级索引和二级索引都采用 8byte 存储每个索引数据。
一级索引 Header
一级索引共由 4096 个 8byte 构成。
每个索引数据由 64 位存储,前 32 位为 IP,后 32 位为 baseIndex。
baseIndex = index / 4096,index 为消息递增序列号。
二级索引
二级索引共由 4095 个 segment 构成,每个 segment 由 4096 个 8byte 构成。
每个索引数据由 64 位存储,前 40 位为存储块的首地址,后 24 位为解压后的块内偏移地址。
一级索引 Header 与二级索引关系
一级索引第一个 8byte 存储可存储魔数(图中用 -1 表示),用于标识文件有效性。
一级索引剩余 4095 个 8byte 分别与二级索引中每个 segment 顺序一一对应。
如何定位一个消息
根据应用名定位对应的索引文件和数据文件。
加载索引文件中的所有一级索引,建立 IP、baseIndex、segmentIndex 的映射表。
从整个索引文件角度看,segmentIndex 是递增的,1 ~ 4095、4097 ~ 8291,以此类推。
根据消息序列号 index 计算得出 baseIndex。
通过 IP、baseIndex 查找映射表,定位 segmentIndex。
计算消息所对应segment的偏移地址:segmentOffset = (index % 4096) * 8,获得索引数据。
根据索引数据中块偏移地址读取压缩的数据块,Snappy 解压后根据块内偏移地址读取消息的二进制数据。
针对类似消息系统的数据存储,索引设计是比较重要的一环,方案并不是唯一的,需要不断推敲和完善。文件存储常用的一些性能优化手段:
批量、顺序写,减少磁盘交互次数。
4K 对齐写入。
数据压缩,常用的压缩算法有 Gzip、Snappy、LZ4。
对象池,避免内存频繁分配。